
Construye tu primer clasificador de Deep Learning con TensorFlow: Ejemplo de razas de perros
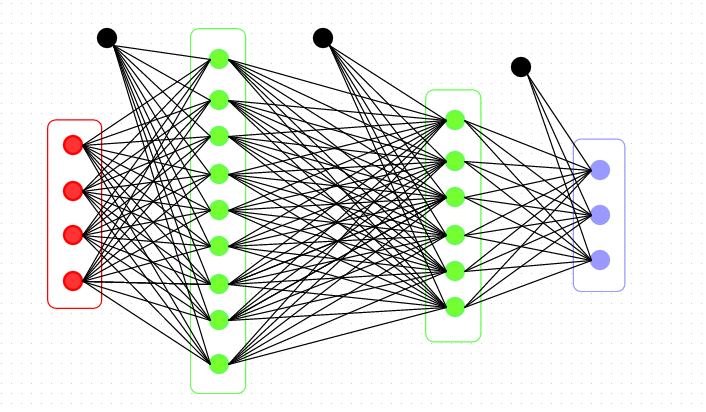
En este artículo, presentaré varias técnicas para que dé los primeros pasos hacia el desarrollo de un algoritmo que podría usarse para un problema clásico de clasificación de imágenes : detectar la raza de un perro a partir de una imagen.
Al final de este artículo, habremos desarrollado un código que aceptará cualquier imagen proporcionada por el usuario como entrada y devolverá una estimación de la raza del perro. Además, si se detecta un ser humano, el algoritmo proporcionará una estimación de la raza de perro que más se asemeja.
1. ¿Qué son las redes neuronales convolucionales?
Las redes neuronales convolucionales (también denominadas CNN o ConvNet) son una clase de redes neuronales profundas que se han adoptado ampliamente en varias aplicaciones de visión artificial e imágenes visuales.
Un famoso caso de aplicación CNN fue detallado en este trabajo de investigación por un equipo de investigación de Stanford en el que demostraron la clasificación de las lesiones cutáneas usando una sola CNN. La Red Neural fue entrenada a partir de imágenes utilizando solo píxeles y etiquetas de enfermedades como entradas.
Las redes neuronales convolucionales constan de múltiples capas diseñadas para requerir un preprocesamiento relativamente pequeño en comparación con otros algoritmos de clasificación de imágenes.
Aprenden usando filtros y aplicándolos a las imágenes. El algoritmo toma un cuadrado pequeño (o ‘ventana’) y comienza a aplicarlo sobre la imagen. Cada filtro permite que la CNN identifique ciertos patrones en la imagen. La CNN busca partes de la imagen donde un filtro coincida con el contenido de la imagen.
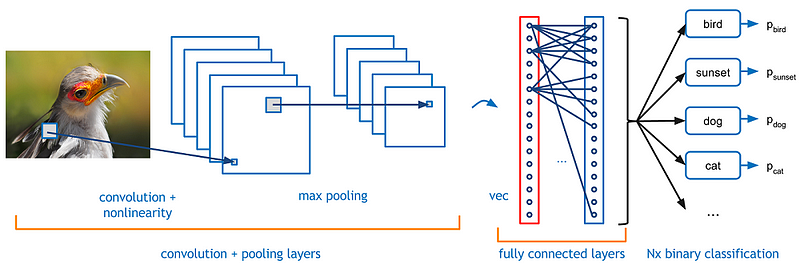
Las primeras capas de la red pueden detectar características simples como líneas, círculos, bordes. En cada capa, la red puede combinar estos hallazgos y aprender continuamente conceptos más complejos a medida que profundizamos en las capas de la red neuronal.
1.1 ¿Qué tipos de capas hay?
La arquitectura general de una CNN consiste en una capa de entrada, capa(s) oculta(s) y una capa de salida. Son varios tipos de capas, por ejemplo, Convolucional, Activación, Pooling, Dropout, Dense y capa SoftMax.
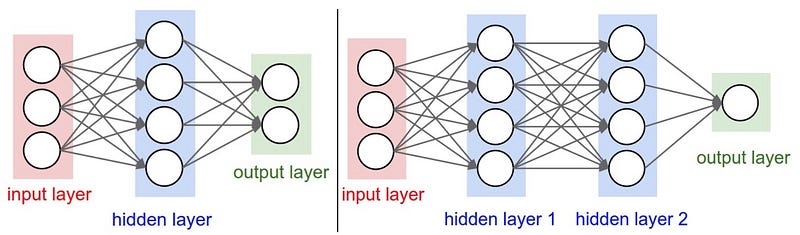
La capa convolucional (o capa Conv) es el núcleo de lo que hace una red neuronal convolucional. La capa Conv consiste en un conjunto de filtros. Cada filtro se puede considerar como un cuadrado pequeño (con un ancho y una altura fijos) que se extiende a través de la profundidad total del volumen de entrada.
Durante cada pasada, el filtro ‘se desplaza’ en el ancho y la altura del volumen de entrada. Este proceso da como resultado un mapa de activación bidimensional que proporciona las respuestas de ese filtro en cada posición espacial.
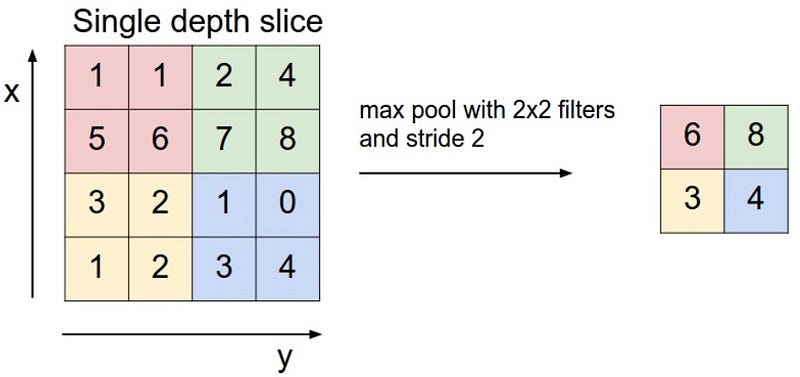
Para evitar un ajuste excesivo, las capas de agrupación se utilizan para aplicar la reducción de muestreo no lineal en los mapas de activación. En otras palabras, agrupar capas es agresivo al descartar información, pero puede ser útil si se usa de forma adecuada. Una capa Pooling a menudo seguiría una o dos Capas Conv en la arquitectura CNN.
Las capas de deserción también se utilizan para reducir el exceso de ajuste, ignoran aleatoriamente ciertas funciones de activación, mientras que las capas densas son capas completamente conectadas y, a menudo, se encuentran al final de la red neuronal.
1.2 ¿Qué son las funciones de activación?
La salida de las capas y de la red neuronal se procesa utilizando una función de activación, que es un nodo que se agrega a las capas de ocultación y a la capa de salida.
A menudo encontrará que la función de activación de ReLu se usa en capas ocultas, mientras que la capa final generalmente consiste en una función de activación de SoftMax. La idea es que al apilar capas de funciones lineales y no lineales, podemos detectar una amplia gama de patrones y predecir con precisión una etiqueta para una imagen determinada.
SoftMax a menudo se encuentra en la capa final que actúa básicamente como un normalizador y produce un vector discreto de distribución de probabilidad, que es genial para nosotros, ya que la salida de la CNN que queremos es una probabilidad de que una imagen se corresponda con una clase en particular.
Cuando se trata de la evaluación del modelo y la evaluación del rendimiento, se elige una función de pérdida. En las CNN para la clasificación de imágenes, a menudo se elige la entropía cruzada categorial (en pocas palabras: corresponde a -log(error)). Existen varios métodos para minimizar el error usando Gradient Descent: en este artículo, confiaremos en “ rmsprop “, que es un método de tasa de aprendizaje adaptativo, como un optimizador con precisión como una métrica.
2. Configuración de los bloques de construcción del algoritmo
Para construir nuestro algoritmo, utilizaremos TensorFlow , Keras (API de redes neuronales que se ejecuta sobre TensorFlow) y OpenCV (biblioteca de visión por computadora).
Los conjuntos de datos de capacitación y prueba también estuvieron disponibles cuando se completó este proyecto (ver Repo de GitHub ).
2.1 Detectando si la imagen contiene un rostro humano
Para detectar si la imagen suministrada es una cara humana, usaremos uno de los algoritmos de detección de rostros de OpenCV . Antes de utilizar cualquiera de los detectores faciales, es un procedimiento estándar convertir las imágenes a escala de grises. A continuación, la
detectMultiScalefunción ejecuta el clasificador almacenado en face_cascadey toma la imagen en escala de grises como parámetro.2.2 Detectando si la imagen contiene un perro
Para detectar si la imagen suministrada contiene una cara de perro, usaremos un modelo ResNet -50 preentrenado utilizando el conjunto de datos de ImageNet que puede clasificar un objeto de una de las 1000 categorías . Dada una imagen, este modelo ResNet-50 preentrenado arroja una predicción para el objeto que está contenido en la imagen.
Cuando se usa TensorFlow como backend, las CNN de Keras requieren una matriz 4D como entrada. La
path_to_tensorfunción siguiente toma una ruta de archivo con valores de cadena a una imagen en color como entrada, la redimensiona a una imagen cuadrada de 224x224 píxeles y devuelve una matriz 4D (denominada "tensor") adecuada para suministrar a una Keras CNN.
Además, todos los modelos pre-entrenados tienen el paso de normalización adicional que debe restar el píxel medio de cada píxel en cada imagen. Esto se implementa en la función importada
preprocess_input.
Como se muestra en el código anterior, para la predicción final obtenemos un número entero correspondiente a la clase de objeto predicha del modelo tomando el argmax del vector de probabilidad pronosticado, que podemos identificar con una categoría de objeto mediante el uso del diccionario deetiquetas ImageNet .
3. Construye tu clasificador CNN usando Transfer Learning
Ahora que tenemos funciones para detectar humanos y perros en imágenes, necesitamos una manera de predecir la raza a partir de las imágenes. En esta sección, crearemos una CNN que clasifique las razas de perros.
Para reducir el tiempo de entrenamiento sin sacrificar la precisión, entrenaremos una CNN usando Transfer Learning , que es un método que nos permite usar Redes que han sido pre-entrenadas en un gran conjunto de datos. Al mantener las primeras capas y solo entrenar las capas recién agregadas, podemos aprovechar el conocimiento adquirido por el algoritmo pre-entrenado y usarlo para nuestra aplicación.
Keras incluye varios modelos de aprendizaje profundo preentrenamiento que se pueden utilizar para la predicción, la extracción de características y el ajuste fino.
3.1 Arquitectura del modelo
Como se mencionó anteriormente, la salida del modelo ResNet-50 va a ser nuestra capa de entrada, llamada características de cuello de botella . En el siguiente bloque de código, extraemos las características del cuello de botella correspondientes a los conjuntos de tren, prueba y validación ejecutando lo siguiente.
Configuraremos nuestra arquitectura de modelo de modo que la última salida convolucional de ResNet-50 se alimente como entrada a nuestro modelo. Solo agregamos una capa Global Pooling común y una capa Fully Connected , donde esta última contiene un nodo para cada categoría de perro y tiene una función de activación de Softmax .
_________________________________________________________________ Layer (type) Output Shape Param # ================================================================= global_average_pooling2d_3 ( (None, 2048) 0 _________________________________________________________________ dense_3 (Dense) (None, 133) 272517 ================================================================= Total params: 272,517 Trainable params: 272,517 Non-trainable params: 0 _________________________________________________________________
Como podemos ver en el resultado del código anterior, ¡terminamos con una red neuronal con 272.517 parámetros!
3.2 Compila y prueba el modelo
Ahora, podemos usar la CNN para probar qué tan bien identifica la raza dentro de nuestro conjunto de datos de prueba de imágenes de perros. Para afinar el modelo, pasamos por 20 iteraciones (o “ épocas “) en las que se ajustan los hiperparámetros del modelo para reducir la función de pérdida ( entropía cruzada categorial ) que se optimiza utilizando la proposición RMS.
Test accuracy: 80.0239%
Provisto de un conjunto de prueba, el algoritmo obtuvo una precisión de prueba del 80% . ¡No está mal!
3.3 Predecir razas de perro con el modelo
Ahora que tenemos el algoritmo, vamos a escribir una función que tome una ruta de imagen como entrada y devuelva la raza de perro que predice nuestro modelo.
4. Probando nuestro clasificador CNN
Ahora, podemos escribir una función que acepta aceptar una ruta de archivo a una imagen y primero determina si la imagen contiene un ser humano, un perro o ninguno.
Si se detecta un perro en la imagen, devuelve la raza predicha. Si se detecta un ser humano en la imagen, devuelve la raza de perro que se asemeja. Si nose detecta ninguno en la imagen, proporcione un resultado que indique un error.
¡Estamos listos para tomar el algoritmo para dar un giro! Probemos el algoritmo en algunas imágenes de muestra:

¡Estas predicciones me parecen acertadas!
En una nota final, observé que el algoritmo es propenso a errores a menos que sea una toma clara de frente con muy poco ruido / información adicional sobre la imagen. Por lo tanto, necesitamos hacer que el algoritmo sea más robusto al ruido. El aumento de imagen puede ser útil para resolver esto, que es un tema que trataré en un artículo futuro.
Arquitecto especialista en gestion de proyectos si necesitas desarrollar algun proyecto en Bogota contactame en el 3006825874 o visita mi pagina en www.arquitectobogota.tk
0 comentarios:
Publicar un comentario